By Jonathan May, University of Southern California
It doesn’t take much to get ChatGPT to make a factual mistake. My son is doing a report on U.S. presidents, so I figured I’d help him out by looking up a few biographies. I tried asking for a list of books about Abraham Lincoln and it did a pretty good job:
Screen capture by Jonathan May., CC BY-ND
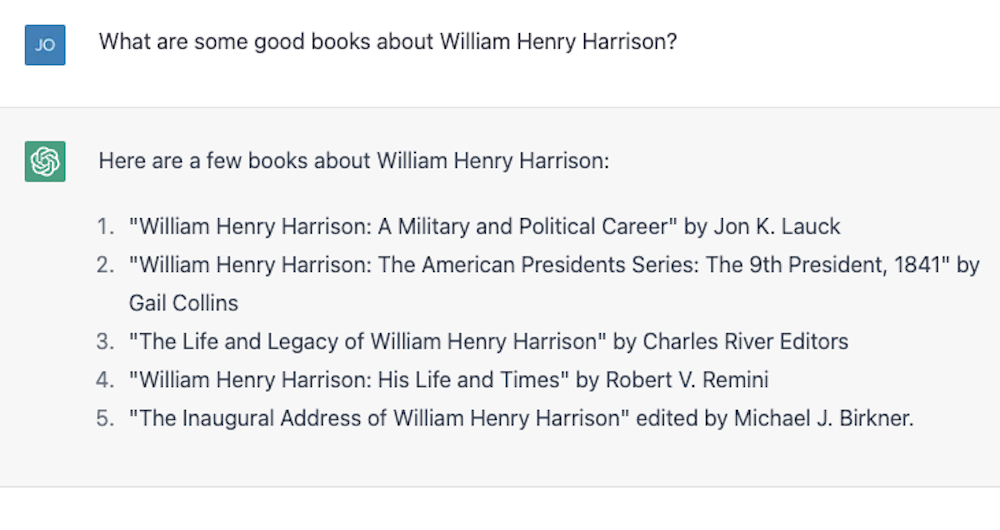
Number 4 isn’t right. Garry Wills famously wrote “Lincoln at Gettysburg,” and Lincoln himself wrote the Emancipation Proclamation, of course, but it’s not a bad start. Then I tried something harder, asking instead about the much more obscure William Henry Harrison, and it gamely provided a list, nearly all of which was wrong.
Screen capture by Jonathan May., CC BY-ND
Numbers 4 and 5 are correct; the rest don’t exist or are not authored by those people. I repeated the exact same exercise and got slightly different results:
Screen capture by Jonathan May., CC BY-ND
This time numbers 2 and 3 are correct and the other three are not actual books or not written by those authors. Number 4, “William Henry Harrison: His Life and Times” is a real book, but it’s by James A. Green, not by Robert Remini, a well-known historian of the Jacksonian age.
I called out the error and ChatGPT eagerly corrected itself and then confidently told me the book was in fact written by Gail Collins (who wrote a different Harrison biography), and then went on to say more about the book and about her. I finally revealed the truth and the machine was happy to run with my correction. Then I lied absurdly, saying during their first hundred days presidents have to write a biography of some former president, and ChatGPT called me out on it. I then lied subtly, incorrectly attributing authorship of the Harrison biography to historian and writer Paul C. Nagel, and it bought my lie.
Free Reports:
When I asked ChatGPT if it was sure I was not lying, it claimed that it’s just an “AI language model” and doesn’t have the ability to verify accuracy. However it modified that claim by saying “I can only provide information based on the training data I have been provided, and it appears that the book ‘William Henry Harrison: His Life and Times’ was written by Paul C. Nagel and published in 1977.”
This is not true.
It may seem from this interaction that ChatGPT was given a library of facts, including incorrect claims about authors and books. After all, ChatGPT’s maker, OpenAI, claims it trained the chatbot on “vast amounts of data from the internet written by humans.”
However, it was almost certainly not given the names of a bunch of made-up books about one of the most mediocre presidents. In a way, though, this false information is indeed based on its training data.
As a computer scientist, I often field complaints that reveal a common misconception about large language models like ChatGPT and its older brethren GPT3 and GPT2: that they are some kind of “super Googles,” or digital versions of a reference librarian, looking up answers to questions from some infinitely large library of facts, or smooshing together pastiches of stories and characters. They don’t do any of that – at least, they were not explicitly designed to.
A language model like ChatGPT, which is more formally known as a “generative pretrained transformer” (that’s what the G, P and T stand for), takes in the current conversation, forms a probability for all of the words in its vocabulary given that conversation, and then chooses one of them as the likely next word. Then it does that again, and again, and again, until it stops.
So it doesn’t have facts, per se. It just knows what word should come next. Put another way, ChatGPT doesn’t try to write sentences that are true. But it does try to write sentences that are plausible.
When talking privately to colleagues about ChatGPT, they often point out how many factually untrue statements it produces and dismiss it. To me, the idea that ChatGPT is a flawed data retrieval system is beside the point. People have been using Google for the past two and a half decades, after all. There’s a pretty good fact-finding service out there already.
In fact, the only way I was able to verify whether all those presidential book titles were accurate was by Googling and then verifying the results. My life would not be that much better if I got those facts in conversation, instead of the way I have been getting them for almost half of my life, by retrieving documents and then doing a critical analysis to see if I can trust the contents.
On the other hand, if I can talk to a bot that will give me plausible responses to things I say, it would be useful in situations where factual accuracy isn’t all that important. A few years ago a student and I tried to create an “improv bot,” one that would respond to whatever you said with a “yes, and” to keep the conversation going. We showed, in a paper, that our bot was better at “yes, and-ing” than other bots at the time, but in AI, two years is ancient history.
I tried out a dialogue with ChatGPT – a science fiction space explorer scenario – that is not unlike what you’d find in a typical improv class. ChatGPT is way better at “yes, and-ing” than what we did, but it didn’t really heighten the drama at all. I felt as if I was doing all the heavy lifting.
After a few tweaks I got it to be a little more involved, and at the end of the day I felt that it was a pretty good exercise for me, who hasn’t done much improv since I graduated from college over 20 years ago.
Screen capture by Jonathan May., CC BY-ND
Sure, I wouldn’t want ChatGPT to appear on “Whose Line Is It Anyway?” and this is not a great “Star Trek” plot (though it’s still less problematic than “Code of Honor”), but how many times have you sat down to write something from scratch and found yourself terrified by the empty page in front of you? Starting with a bad first draft can break through writer’s block and get the creative juices flowing, and ChatGPT and large language models like it seem like the right tools to aid in these exercises.
And for a machine that is designed to produce strings of words that sound as good as possible in response to the words you give it – and not to provide you with information – that seems like the right use for the tool.
About the Author:
Jonathan May, Research Associate Professor of Computer Science, University of Southern California
This article is republished from The Conversation under a Creative Commons license. Read the original article.
By ForexTime FXTM’s USDInd ↑ 2% MTD Dollar best performing G10 currency MTD Geopolitical risk…
By JustMarkets The US stock market concluded Thursday’s session in the red as the escalating…
By Analytical Department RoboForex EUR/USD is holding near 1.1620 on Friday, with the US dollar…
By JustMarkets The US stock market rose on Wednesday. By the end of the day,…
By Daniele D'Alvia, Queen Mary University of London When a conflict escalates, financial markets respond…
By Analytical Department RoboForex GBP/USD contracted to 1.3350 on Thursday, with the pound remaining under…
This website uses cookies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}