Amazon’s $4bn investment into a ChatGPT rival reinforces why almost all investors should have some artificial intelligence (AI) exposure in their investment mix, says the CEO of one of the world’s largest independent financial advisory, asset management and fintech organizations.
The comments from Nigel Green of deVere Group comes as e-commerce giant Amazon said on Monday it will invest $4 billion in Anthropic and take a minority ownership position. Anthropic was founded by former OpenAI (the company behind ChatGPT) executives, and recently debuted its new AI chatbot named Claude 2.
He says: “This move highlights how the big tech titan is stepping up its rivalry with other giants Microsoft, Google and Nvidia in the AI space.
“The AI Race is on, with the big tech firms racing to lead in the development, deployment, and utilisation of artificial intelligence technologies.
“AI is going to reshape whole industries and fuel innovation – and this makes it crucial for investors to pay attention and why almost all investors need exposure to AI investments in their portfolios.”
While it seems that the AI hype is everywhere now, we are still very early in the AI era. Investors, says the deVere CEO, should act now to have the ‘early advantage’.
“Getting in early allows investors to establish a competitive advantage over latecomers. They can secure favourable entry points and lower purchase prices, maximizing their potential profits.
“This tech has the potential to disrupt existing industries or create entirely new ones. Early investors are likely to benefit from the exponential growth that often accompanies the adoption of such technologies. As these innovations gain traction, their valuations could skyrocket, resulting in significant returns on investment,” he notes.
While AI is The Big Story currently, investors should, as always, remain diversified across asset classes, sectors and regions in order to maximise returns per unit of risk (volatility) incurred.
Diversification remains investors’ best tool for long-term financial success. As a strategy it has been proven to reduce risk, smooth-out volatility, exploit differing market conditions, maximise long-term returns and protect against unforeseen external events.
Of the latest Amazon investment, Nigel Green concludes: “AI is not just another technology trend; it is a game-changer. Investors need to pay attention and include it as part of their mix.”
About:
deVere Group is one of the world’s largest independent advisors of specialist global financial solutions to international, local mass affluent, and high-net-worth clients. It has a network of offices across the world, over 80,000 clients and $12bn under advisement.
Every time a scientist runs an experiment, or a social scientist does a survey, or a humanities scholar analyzes a text, they generate data. Science runs on data – without it, we wouldn’t have the James Webb Space Telescope’s stunning images, disease-preventing vaccines or an evolutionary tree that traces the lineages of all life.
This scholarship generates an unimaginable amount of data – so how do researchers keep track of it? And how do they make sure that it’s accessible for use by both humans and machines?
To improve and advance science, scientists need to be able to reproduce others’ data or combine data from multiple sources to learn something new.
Accessible and usable data can help scientists reproduce prior results. Doing so is an important part of the scientific process, as this TED-Ed video explains.
Any kind of sharing requires management. If your neighbor needs to borrow a tool or an ingredient, you have to know whether you have it and where you keep it. Research data might be on a graduate student’s laptop, buried in a professor’s USB collection or saved more permanently within an online data repository.
I’m an information scientist who studies other scientists. More precisely, I study how scientists think about research data and the ways that they interact with their own data and data from others. I also teach students how to manage their own or others’ data in ways that advance knowledge.
Research data management
Research data management is an area of scholarship that focuses on data discovery and reuse. As a field, it encompasses research data services, resources and cyberinfrastructure. For example, one type of infrastructure, the data repository, gives researchers a place to deposit their data for long-term storage so that others can find it. In short, research data management encompasses the data’s life cycle from cradle to grave to reincarnation in the next study.
Proper research data management also allows scientists to use the data already out there rather than recollecting data that already exists, which saves time and resources.
Scientists and data managers can work together to redesign the systems scientists use to make data discovery and preservation easier. In particular, integrating AI can make this data more accessible and reusable.
Artificially intelligent data management
Many of these new standards for research data management also stem from an increased use of AI, including machine learning, across data-driven fields. AI makes it highly desirable for any data to be machine-actionable – that is, usable by machines without human intervention. Now, scholars can consider machines not only as tools but also as potential autonomous data reusers and collaborators.
The key to machine-actionable data is metadata. Metadata are the descriptions scientists set for their data and may include elements such as creator, date, coverage and subject. Minimal metadata is minimally useful, but correct and complete standardized metadata makes data more useful for both people and machines.
It takes a cadre of research data managers and librarians to make machine-actionable data a reality. These information professionals work to facilitate communication between scientists and systems by ensuring the quality, completeness and consistency of shared data.
The FAIR data principles, created by a group of researchers called FORCE11 in 2016 and used across the world, provide guidance on how to enable data reuse by machines and humans. FAIR data is findable, accessible, interoperable and reusable – meaning it has robust and complete metadata.
In the past, I’ve studied how scientists discover and reuse data. I found that scientists tend to use mental shortcuts when they’re looking for data – for example, they may go back to familiar and trusted sources or search for certain key terms they’ve used before. Ideally, my team could build this decision-making process of experts and remove as many biases as possible to improve AI. The automation of these mental shortcuts should reduce the time-consuming chore of locating the right data.
Data management plans
But there’s still one piece of research data management that AI can’t take over. Data management plans describe the what, where, when, why and who of managing research data. Scientists fill them out, and they outline the roles and activities for managing research data during and long after research ends. They answer questions like, “Who is responsible for long-term preservation,” “Where will the data live,” “How do I keep my data secure,” and “Who pays for all of that?”
Grant proposals for nearly all funding agencies across countries now require data management plans. These plans signal to scientists that their data is valuable and important enough to the community to share. Also, the plans help funding agencies keep tabs on the research and investigate any potential misconduct. But most importantly, they help scientists make sure their data stays accessible for many years.
Making all research data as FAIR and open as possible will improve the scientific process. And having access to more data opens up the possibility for more informed discussions on how to promote economic development, improve the stewardship of natural resources, enhance public health, and how to responsibly and ethically develop technologies that will improve lives. All intelligence, artificial or otherwise, will benefit from better organization, access and use of research data.
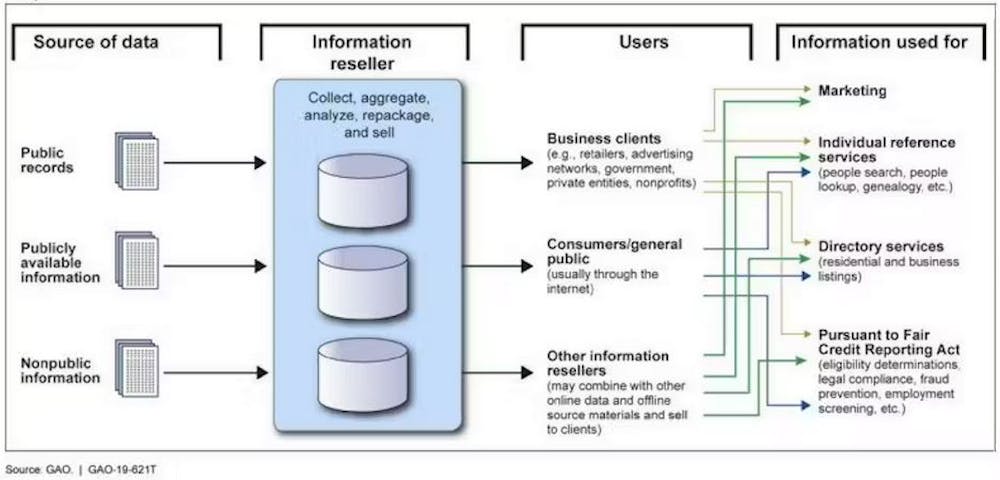
Numerous government agencies, including the FBI, Department of Defense, National Security Agency, Treasury Department, Defense Intelligence Agency, Navy and Coast Guard, have purchased vast amounts of U.S. citizens’ personal information from commercial data brokers. The revelation was published in a partially declassified, internal Office of the Director of National Intelligence report released on June 9, 2023.
The report shows the breathtaking scale and invasive nature of the consumer data market and how that market directly enables wholesale surveillance of people. The data includes not only where you’ve been and who you’re connected to, but the nature of your beliefs and predictions about what you might do in the future. The report underscores the grave risks the purchase of this data poses, and urges the intelligence community to adopt internal guidelines to address these problems.
As a privacy, electronic surveillance and technology law attorney, researcher and law professor, I have spent years researching, writing and advising about the legal issues the report highlights.
These issues are increasingly urgent. Today’s commercially available information, coupled with the now-ubiquitous decision-making artificial intelligence and generative AI like ChatGPT, significantly increases the threat to privacy and civil liberties by giving the government access to sensitive personal information beyond even what it could collect through court-authorized surveillance.
What is commercially available information?
The drafters of the report take the position that commercially available information is a subset of publicly available information. The distinction between the two is significant from a legal perspective. Publicly available information is information that is already in the public domain. You could find it by doing a little online searching.
Commercially available information is different. It is personal information collected from a dizzying array of sources by commercial data brokers that aggregate and analyze it, then make it available for purchase by others, including governments. Some of that information is private, confidential or otherwise legally protected.
The commercial data market collects and packages vast amounts of data and sells it for various commercial, private and government uses. Government Accounting Office
The sources and types of data for commercially available information are mind-bogglingly vast. They include public records and other publicly available information. But far more information comes from the nearly ubiquitous internet-connected devices in people’s lives, like cellphones, smart home systems, cars and fitness trackers. These all harness data from sophisticated, embedded sensors, cameras and microphones. Sources also include data from apps, online activity, texts and emails, and even health care provider websites.
This data provides companies and governments a window into the “Internet of Behaviors,” a combination of data collection and analysis aimed at understanding and predicting people’s behavior. It pulls together a wide range of data, including location and activities, and uses scientific and technological approaches, including psychology and machine learning, to analyze that data. The Internet of Behaviors provides a map of what each person has done, is doing and is expected to do, and provides a means to influence a person’s behavior.
Smart homes could be good for your wallet and good for the environment, but really bad for your privacy.
Better, cheaper and unrestricted
The rich depths of commercially available information, analyzed with powerful AI, provide unprecedented power, intelligence and investigative insights. The information is a cost-effective way to surveil virtually everyone, plus it provides far more sophisticated data than traditional electronic surveillance tools or methods like wiretapping and location tracking.
Complying with these laws takes time and money, plus electronic surveillance law restricts what, when and how data can be collected. Commercially available information is cheaper to obtain, provides far richer data and analysis, and is subject to little oversight or restriction compared to when the same data is collected directly by the government.
The threats
Technology and the burgeoning volume of commercially available information allow various forms of the information to be combined and analyzed in new ways to understand all aspects of your life, including preferences and desires.
How the collection, aggregation and sale of your data violates your privacy.
The Office of the Director of National Intelligence report warns that the increasing volume and widespread availability of commercially available information poses “significant threats to privacy and civil liberties.” It increases the power of the government to surveil its citizens outside the bounds of law, and it opens the door to the government using that data in potentially unlawful ways. This could include using location data obtained via commercially available information rather than a warrant to investigate and prosecute someone for abortion.
The report also captures both how widespread government purchases of commercially available information are and how haphazard government practices around the use of the information are. The purchases are so pervasive and agencies’ practices so poorly documented that the Office of the Director of National Intelligence cannot even fully determine how much and what types of information agencies are purchasing, and what the various agencies are doing with the data.
Is it legal?
The question of whether it’s legal for government agencies to purchase commercially available information is complicated by the array of sources and complex mix of data it contains.
There is no legal prohibition on the government collecting information already disclosed to the public or otherwise publicly available. But the nonpublic information listed in the declassified report includes data that U.S. law typically protects. The nonpublic information’s mix of private, sensitive, confidential or otherwise lawfully protected data makes collection a legal gray area.
Despite decades of increasingly sophisticated and invasive commercial data aggregation, Congress has not passed a federal data privacy law. The lack of federal regulation around data creates a loophole for government agencies to evade electronic surveillance law. It also allows agencies to amass enormous databases that AI systems learn from and use in often unrestricted ways. The resulting erosion of privacy has been a concern for more than a decade.
Throttling the data pipeline
The Office of the Director of National Intelligence report acknowledges the stunning loophole that commercially available information provides for government surveillance: “The government would never have been permitted to compel billions of people to carry location tracking devices on their persons at all times, to log and track most of their social interactions, or to keep flawless records of all their reading habits. Yet smartphones, connected cars, web tracking technologies, the Internet of Things, and other innovations have had this effect without government participation.”
However, it isn’t entirely correct to say “without government participation.” The legislative branch could have prevented this situation by enacting data privacy laws, more tightly regulating commercial data practices, and providing oversight in AI development. Congress could yet address the problem. Representative Ted Lieu has introduced the a bipartisan proposal for a National AI Commission, and Senator Chuck Schumer has proposed an AI regulation framework.
Effective data privacy laws would keep your personal information safer from government agencies and corporations, and responsible AI regulation would block them from manipulating you.
In 2022, an AI-generated work of art won the Colorado State Fair’s art competition. The artist, Jason Allen, had used Midjourney – a generative AI system trained on art scraped from the internet – to create the piece. The process was far from fully automated: Allen went through some 900 iterations over 80 hours to create and refine his submission.
Yet his use of AI to win the art competition triggered a heated backlash online, with one Twitter user claiming, “We’re watching the death of artistry unfold right before our eyes.”
As generative AI art tools like Midjourney and Stable Diffusion have been thrust into the limelight, so too have questions about ownership and authorship.
These tools’ generative ability is the result of training them with scores of prior artworks, from which the AI learns how to create artistic outputs.
Should the artists whose art was scraped to train the models be compensated? Who owns the images that AI systems produce? Is the process of fine-tuning prompts for generative AI a form of authentic creative expression?
On one hand, technophiles rave over work like Allen’s. But on the other, many working artists consider the use of their art to train AI to be exploitative.
We’re part of a team of 14 experts across disciplines that just published a paper on generative AI in Science magazine. In it, we explore how advances in AI will affect creative work, aesthetics and the media. One of the key questions that emerged has to do with U.S. copyright laws, and whether they can adequately deal with the unique challenges of generative AI.
Copyright laws were created to promote the arts and creative thinking. But the rise of generative AI has complicated existing notions of authorship.
Still from ‘All watched over by machines of loving grace’ by Memo Akten, 2021. Created using custom AI software. Memo Akten, CC BY-SA
Photography serves as a helpful lens
Generative AI might seem unprecedented, but history can act as a guide.
Take the emergence of photography in the 1800s. Before its invention, artists could only try to portray the world through drawing, painting or sculpture. Suddenly, reality could be captured in a flash using a camera and chemicals. As with generative AI, many argued that photography lacked artistic merit. In 1884, the U.S. Supreme Court weighed in on the issue and found that cameras served as tools that an artist could use to give an idea visible form; the “masterminds” behind the cameras, the court ruled, should own the photographs they create.
Unlike inanimate cameras, AI possesses capabilities – like the ability to convert basic instructions into impressive artistic works – that make it prone to anthropomorphization. Even the term “artificial intelligence” encourages people to think that these systems have humanlike intent or even self-awareness.
This led some people to wonder whether AI systems can be “owners.” But the U.S. Copyright Office has stated unequivocally that only humans can hold copyrights.
So who can claim ownership of images produced by AI? Is it the artists whose images were used to train the systems? The users who type in prompts to create images? Or the people who build the AI systems?
Infringement or fair use?
While artists draw obliquely from past works that have educated and inspired them in order to create, generative AI relies on training data to produce outputs.
This training data consists of prior artworks, many of which are protected by copyright law and which have been collected without artists’ knowledge or consent. Using art in this way might violate copyright law even before the AI generates a new work.
Still from ‘All watched over by machines of loving grace’ by Memo Akten, 2021. Created using custom AI software. Memo Akten, CC BY-SA
For Jason Allen to create his award-winning art, Midjourney was trained on 100 million prior works.
Was that a form of infringement? Or was it a new form of “fair use,” a legal doctrine that permits the unlicensed use of protected works if they’re sufficiently transformed into something new?
While AI systems do not contain literal copies of the training data, they do sometimes manage to recreate works from the training data, complicating this legal analysis.
Will contemporary copyright law favor end users and companies over the artists whose content is in the training data?
To mitigate this concern, some scholars propose new regulations to protect and compensate artists whose work is used for training. These proposals include a right for artists to opt out of their data’s being used for generative AI or a way to automatically compensate artists when their work is used to train an AI.
Muddled ownership
Training data, however, is only part of the process. Frequently, artists who use generative AI tools go through many rounds of revision to refine their prompts, which suggests a degree of originality.
Answering the question of who should own the outputs requires looking into the contributions of all those involved in the generative AI supply chain.
The legal analysis is easier when an output is different from works in the training data. In this case, whoever prompted the AI to produce the output appears to be the default owner.
However, copyright law requires meaningful creative input – a standard satisfied by clicking the shutter button on a camera. It remains unclear how courts will decide what this means for the use of generative AI. Is composing and refining a prompt enough?
Matters are more complicated when outputs resemble works in the training data. If the resemblance is based only on general style or content, it is unlikely to violate copyright, because style is not copyrightable.
The illustrator Hollie Mengert encountered this issue firsthand when her unique style was mimicked by generative AI engines in a way that did not capture what, in her eyes, made her work unique. Meanwhile, the singer Grimes embraced the tech, “open-sourcing” her voice and encouraging fans to create songs in her style using generative AI.
If an output contains major elements from a work in the training data, it might infringe on that work’s copyright. Recently, the Supreme Court ruled that Andy Warhol’s drawing of a photograph was not permitted by fair use. That means that using AI to just change the style of a work – say, from a photo to an illustration – is not enough to claim ownership over the modified output.
While copyright law tends to favor an all-or-nothing approach, scholars at Harvard Law School have proposed new models of joint ownership that allow artists to gain some rights in outputs that resemble their works.
In many ways, generative AI is yet another creative tool that allows a new group of people access to image-making, just like cameras, paintbrushes or Adobe Photoshop. But a key difference is this new set of tools relies explicitly on training data, and therefore creative contributions cannot easily be traced back to a single artist.
The ways in which existing laws are interpreted or reformed – and whether generative AI is appropriately treated as the tool it is – will have real consequences for the future of creative expression.
Generative AI is the hot new technology behind chatbots and image generators. But how hot is it making the planet?
As an AI researcher, I often worry about the energy costs of building artificial intelligence models. The more powerful the AI, the more energy it takes. What does the emergence of increasingly more powerful generative AI models mean for society’s future carbon footprint?
“Generative” refers to the ability of an AI algorithm to produce complex data. The alternative is “discriminative” AI, which chooses between a fixed number of options and produces just a single number. An example of a discriminative output is choosing whether to approve a loan application.
Generative AI can create much more complex outputs, such as a sentence, a paragraph, an image or even a short video. It has long been used in applications like smart speakers to generate audio responses, or in autocomplete to suggest a search query. However, it only recently gained the ability to generate humanlike language and realistic photos.
AI chatbots and image generators run on thousands of computers housed in data centers like this Google facility in Oregon. Tony Webster/Wikimedia, CC BY-SA
Using more power than ever
The exact energy cost of a single AI model is difficult to estimate, and includes the energy used to manufacture the computing equipment, create the model and use the model in production. In 2019, researchers found that creating a generative AI model called BERT with 110 million parameters consumed the energy of a round-trip transcontinental flight for one person. The number of parameters refers to the size of the model, with larger models generally being more skilled. Researchers estimated that creating the much larger GPT-3, which has 175 billion parameters, consumed 1,287 megawatt hours of electricity and generated 552 tons of carbon dioxide equivalent, the equivalent of 123 gasoline-powered passenger vehicles driven for one year. And that’s just for getting the model ready to launch, before any consumers start using it.
Size is not the only predictor of carbon emissions. The open-access BLOOM model, developed by the BigScience project in France, is similar in size to GPT-3 but has a much lower carbon footprint, consuming 433 MWh of electricity in generating 30 tons of CO2eq. A study by Google found that for the same size, using a more efficient model architecture and processor and a greener data center can reduce the carbon footprint by 100 to 1,000 times.
Larger models do use more energy during their deployment. There is limited data on the carbon footprint of a single generative AI query, but some industry figures estimate it to be four to five times higher than that of a search engine query. As chatbots and image generators become more popular, and as Google and Microsoft incorporate AI language models into their search engines, the number of queries they receive each day could grow exponentially.
AI bots for search
A few years ago, not many people outside of research labs were using models like BERT or GPT. That changed on Nov. 30, 2022, when OpenAI released ChatGPT. According to the latest available data, ChatGPT had over 1.5 billion visits in March 2023. Microsoft incorporated ChatGPT into its search engine, Bing, and made it available to everyone on May 4, 2023. If chatbots become as popular as search engines, the energy costs of deploying the AIs could really add up. But AI assistants have many more uses than just search, such as writing documents, solving math problems and creating marketing campaigns.
Another problem is that AI models need to be continually updated. For example, ChatGPT was only trained on data from up to 2021, so it does not know about anything that happened since then. The carbon footprint of creating ChatGPT isn’t public information, but it is likely much higher than that of GPT-3. If it had to be recreated on a regular basis to update its knowledge, the energy costs would grow even larger.
One upside is that asking a chatbot can be a more direct way to get information than using a search engine. Instead of getting a page full of links, you get a direct answer as you would from a human, assuming issues of accuracy are mitigated. Getting to the information quicker could potentially offset the increased energy use compared to a search engine.
Ways forward
The future is hard to predict, but large generative AI models are here to stay, and people will probably increasingly turn to them for information. For example, if a student needs help solving a math problem now, they ask a tutor or a friend, or consult a textbook. In the future, they will probably ask a chatbot. The same goes for other expert knowledge such as legal advice or medical expertise.
While a single large AI model is not going to ruin the environment, if a thousand companies develop slightly different AI bots for different purposes, each used by millions of customers, the energy use could become an issue. More research is needed to make generative AI more efficient. The good news is that AI can run on renewable energy. By bringing the computation to where green energy is more abundant, or scheduling computation for times of day when renewable energy is more available, emissions can be reduced by a factor of 30 to 40, compared to using a grid dominated by fossil fuels.
Finally, societal pressure may be helpful to encourage companies and research labs to publish the carbon footprints of their AI models, as some already do. In the future, perhaps consumers could even use this information to choose a “greener” chatbot.
Artificial Intelligence-powered tools, such as ChatGPT, have the potential to revolutionize the efficiency, effectiveness and speed of the work humans do.
And this is true in financial markets as much as in sectors like health care, manufacturing and pretty much every other aspect of our lives.
I’ve been researching financial markets and algorithmic trading for 14 years. While AI offers lots of benefits, the growing use of these technologies in financial markets also points to potential perils. A look at Wall Street’s past efforts to speed up trading by embracing computers and AI offers important lessons on the implications of using them for decision-making.
Program trading fuels Black Monday
In the early 1980s, fueled by advancements in technology and financial innovations such as derivatives, institutional investors began using computer programs to execute trades based on predefined rules and algorithms. This helped them complete large trades quickly and efficiently.
Back then, these algorithms were relatively simple and were primarily used for so-called index arbitrage, which involves trying to profit from discrepancies between the price of a stock index – like the S&P 500 – and that of the stocks it’s composed of.
As technology advanced and more data became available, this kind of program trading became increasingly sophisticated, with algorithms able to analyze complex market data and execute trades based on a wide range of factors. These program traders continued to grow in number on the largey unregulated trading freeways – on which over a trillion dollars worth of assets change hands every day – causing market volatility to increase dramatically.
Eventually this resulted in the massive stock market crash in 1987 known as Black Monday. The Dow Jones Industrial Average suffered what was at the time the biggest percentage drop in its history, and the pain spread throughout the globe.
In response, regulatory authorities implemented a number of measures to restrict the use of program trading, including circuit breakers that halt trading when there are significant market swings and other limits. But despite these measures, program trading continued to grow in popularity in the years following the crash.
HFT: Program trading on steroids
Fast forward 15 years, to 2002, when the New York Stock Exchange introduced a fully automated trading system. As a result, program traders gave way to more sophisticated automations with much more advanced technology: High-frequency trading.
HFT uses computer programs to analyze market data and execute trades at extremely high speeds. Unlike program traders that bought and sold baskets of securities over time to take advantage of an arbitrage opportunity – a difference in price of similar securities that can be exploited for profit – high-frequency traders use powerful computers and high-speed networks to analyze market data and execute trades at lightning-fast speeds. High-frequency traders can conduct trades in approximately one 64-millionth of a second, compared with the several seconds it took traders in the 1980s.
These trades are typically very short term in nature and may involve buying and selling the same security multiple times in a matter of nanoseconds. AI algorithms analyze large amounts of data in real time and identify patterns and trends that are not immediately apparent to human traders. This helps traders make better decisions and execute trades at a faster pace than would be possible manually.
Another important application of AI in HFT is natural language processing, which involves analyzing and interpreting human language data such as news articles and social media posts. By analyzing this data, traders can gain valuable insights into market sentiment and adjust their trading strategies accordingly.
Benefits of AI trading
These AI-based, high-frequency traders operate very differently than people do.
The human brain is slow, inaccurate and forgetful. It is incapable of quick, high-precision, floating-point arithmetic needed for analyzing huge volumes of data for identifying trade signals. Computers are millions of times faster, with essentially infallible memory, perfect attention and limitless capability for analyzing large volumes of data in split milliseconds.
And, so, just like most technologies, HFT provides several benefits to stock markets.
These traders typically buy and sell assets at prices very close to the market price, which means they don’t charge investors high fees. This helps ensure that there are always buyers and sellers in the market, which in turn helps to stabilize prices and reduce the potential for sudden price swings.
High-frequency trading can also help to reduce the impact of market inefficiencies by quickly identifying and exploiting mispricing in the market. For example, HFT algorithms can detect when a particular stock is undervalued or overvalued and execute trades to take advantage of these discrepancies. By doing so, this kind of trading can help to correct market inefficiencies and ensure that assets are priced more accurately.
The downsides
But speed and efficiency can also cause harm.
HFT algorithms can react so quickly to news events and other market signals that they can cause sudden spikes or drops in asset prices.
Additionally, HFT financial firms are able to use their speed and technology to gain an unfair advantage over other traders, further distorting market signals. The volatility created by these extremely sophisticated AI-powered trading beasts led to the so-called flash crash in May 2010, when stocks plunged and then recovered in a matter of minutes – erasing and then restoring about $1 trillion in market value.
The speed and efficiency with which high-frequency traders analyze the data mean that even a small change in market conditions can trigger a large number of trades, leading to sudden price swings and increased volatility.
In addition, research I published with several other colleagues in 2021 shows that most high-frequency traders use similar algorithms, which increases the risk of market failure. That’s because as the number of these traders increases in the marketplace, the similarity in these algorithms can lead to similar trading decisions.
This means that all of the high-frequency traders might trade on the same side of the market if their algorithms release similar trading signals. That is, they all might try to sell in case of negative news or buy in case of positive news. If there is no one to take the other side of the trade, markets can fail.
Enter ChatGPT
That brings us to a new world of ChatGPT-powered trading algorithms and similar programs. They could take the problem of too many traders on the same side of a deal and make it even worse.
In general, humans, left to their own devices, will tend to make a diverse range of decisions. But if everyone’s deriving their decisions from a similar artificial intelligence, this can limit the diversity of opinion.
Consider an extreme, nonfinancial situation in which everyone depends on ChatGPT to decide on the best computer to buy. Consumers are already very prone to herding behavior, in which they tend to buy the same products and models. For example, reviews on Yelp, Amazon and so on motivate consumers to pick among a few top choices.
Since decisions made by the generative AI-powered chatbot are based on past training data, there would be a similarity in the decisions suggested by the chatbot. It is highly likely that ChatGPT would suggest the same brand and model to everyone. This might take herding to a whole new level and could lead to shortages in certain products and service as well as severe price spikes.
This becomes more problematic when the AI making the decisions is informed by biased and incorrect information. AI algorithms can reinforce existing biases when systems are trained on biased, old or limited data sets. And ChatGPT and similar tools have been criticized for making factual errors.
In addition, since market crashes are relatively rare, there isn’t much data on them. Since generative AIs depend on data training to learn, their lack of knowledge about them could make them more likely to happen.
For now, at least, it seems most banks won’t be allowing their employees to take advantage of ChatGPT and similar tools. Citigroup, Bank of America, Goldman Sachs and several other lenders have already banned their use on trading-room floors, citing privacy concerns.
But I strongly believe banks will eventually embrace generative AI, once they resolve concerns they have with it. The potential gains are too significant to pass up – and there’s a risk of being left behind by rivals.
But the risks to financial markets, the global economy and everyone are also great, so I hope they tread carefully.
The famous first image of a black hole just got two times sharper. A research team used artificial intelligence to dramatically improve upon its first image from 2019, which now shows the black hole at the center of the M87 galaxy as darker and bigger than the first image depicted.
Since then, AI has spread into every field of astronomy. As the technology has become more powerful, AI algorithms have begun helping astronomers tame massive data sets and discover new knowledge about the universe.
Better telescopes, more data
As long as astronomy has been a science, it has involved trying to make sense of the multitude of objects in the night sky. That was relatively simple when the only tools were the naked eye or a simple telescope, and all that could be seen were a few thousand stars and a handful of planets.
A hundred years ago, Edwin Hubble used newly built telescopes to show that the universe is filled with not just stars and clouds of gas, but countless galaxies. As telescopes have continued to improve, the sheer number of celestial objects humans can see and the amount of data astronomers need to sort through have both grown exponentially, too.
For example, the soon-to-be-completed Vera Rubin Observatory in Chile will make images so large that it would take 1,500 high-definition TV screens to view each one in its entirety. Over 10 years it is expected to generate 0.5 exabytes of data – about 50,000 times the amount of information held in all of the books contained within the Library of Congress.
There are 20 telescopes with mirrors larger than 20 feet (6 meters) in diameter. AI algorithms are the only way astronomers could ever hope to work through all of the data available to them today. There are a number of ways AI is proving useful in processing this data.
One of the earliest uses of AI in astronomy was to pick out the multitude of faint galaxies hidden in the background of images. ESA/Webb, NASA & CSA, J. Rigby, CC BY
Picking out patterns
Astronomy often involves looking for needles in a haystack. About 99% of the pixels in an astronomical image contain background radiation, light from other sources or the blackness of space – only 1% have the subtle shapes of faint galaxies.
AI algorithms – in particular, neural networks that use many interconnected nodes and are able to learn to recognize patterns – are perfectly suited for picking out the patterns of galaxies. Astronomers began using neural networks to classify galaxies in the early 2010s. Now the algorithms are so effective that they can classify galaxies with an accuracy of 98%.
This story has been repeated in other areas of astronomy. Astronomers working on SETI, the Search for Extraterrestrial Intelligence, use radio telescopes to look for signals from distant civilizations. Early on, radio astronomers scanned charts by eye to look for anomalies that couldn’t be explained. More recently, researchers harnessed 150,000 personal computers and 1.8 million citizen scientists to look for artificial radio signals. Now, researchers are using AI to sift through reams of data much more quickly and thoroughly than people can. This has allowed SETI efforts to cover more ground while also greatly reducing the number of false positive signals.
AI has proved itself to be excellent at identifying known objects – like galaxies or exoplanets – that astronomers tell it to look for. But it is also quite powerful at finding objects or phenomena that are theorized but have not yet been discovered in the real world.
Teams have used this approach to detect new exoplanets, learn about the ancestral stars that led to the formation and growth of the Milky Way, and predict the signatures of new types of gravitational waves.
To do this, astronomers first use AI to convert theoretical models into observational signatures – including realistic levels of noise. They then use machine learning to sharpen the ability of AI to detect the predicted phenomena.
Finally, radio astronomers have also been using AI algorithms to sift through signals that don’t correspond to known phenomena. Recently a team from South Africa found a unique object that may be a remnant of the explosive merging of two supermassive black holes. If this proves to be true, the data will allow a new test of general relativity – Albert Einstein’s description of space-time.
The team that first imaged a black hole, at left, used AI to generate a sharper version of the image, at right, showing the black hole to be larger than originally thought. Medeiros et al 2023, CC BY-ND
Making predictions and plugging holes
As in many areas of life recently, generative AI and large language models like ChatGPT are also making waves in the astronomy world.
The team that created the first image of a black hole in 2019 used a generative AI to produce its new image. To do so, it first taught an AI how to recognize black holes by feeding it simulations of many kinds of black holes. Then, the team used the AI model it had built to fill in gaps in the massive amount of data collected by the radio telescopes on the black hole M87.
Using this simulated data, the team was able to create a new image that is two times sharper than the original and is fully consistent with the predictions of general relativity.
Astronomers are also turning to AI to help tame the complexity of modern research. A team from the Harvard-Smithsonian Center for Astrophysics created a language model called astroBERT to read and organize 15 million scientific papers on astronomy. Another team, based at NASA, has even proposed using AI to prioritize astronomy projects, a process that astronomers engage in every 10 years.
As AI has progressed, it has become an essential tool for astronomers. As telescopes get better, as data sets get larger and as AIs continue to improve, it is likely that this technology will play a central role in future discoveries about the universe.
It turns out that pop stars Drake and The Weeknd didn’t suddenly drop a new track that went viral on TikTok and YouTube in April 2023. The photograph that won an international photography competition that same month wasn’t a real photograph. And the image of Pope Francis sporting a Balenciaga jacket that appeared in March 2023? That was also a fake.
All were made with the help of generative AI, the new technology that can generate humanlike text, audio and images on demand through programs such as ChatGPT, Midjourney and Bard, among others.
There’s certainly something unsettling about the ease with which people can be duped by these fakes, and I see it as a harbinger of an authenticity crisis that raises some difficult questions.
How will voters know whether a video of a political candidate saying something offensive was real or generated by AI? Will people be willing to pay artists for their work when AI can create something visually stunning? Why follow certain authors when stories in their writing style will be freely circulating on the internet?
I’ve been seeing the anxiety play out all around me at Stanford University, where I’m a professor and also lead a large generative AI and education initiative.
With text, image, audio and video all becoming easier for anyone to produce through new generative AI tools, I believe people are going to need to reexamine and recalibrate how authenticity is judged in the first place.
Fortunately, social science offers some guidance.
The many faces of authenticity
Long before generative AI and ChatGPT rose to the fore, people had been probing what makes something feel authentic.
When a real estate agent is gushing over a property they are trying to sell you, are they being authentic or just trying to close the deal? Is that stylish acquaintance wearing authentic designer fashion or a mass-produced knock-off? As you mature, how do you discover your authentic self?
These are not just philosophical exercises. Neuroscience research has shown that believing a piece of art is authentic will activate the brain’s reward centers in ways that viewing something you’ve been told is a forgery won’t.
Authenticity also matters because it is a social glue that reinforces trust. Take the social media misinformation crisis, in which fake news has been inadvertently spread and authentic news decreed fake.
In short, authenticity matters, for both individuals and society as a whole.
One of those is historical authenticity, or whether an object is truly from the time, place and person someone claims it to be. An actual painting made by Rembrandt would have historical authenticity; a modern forgery would not.
A second dimension of authenticity is the kind that plays out when, say, a restaurant in Japan offers exceptional and authentic Neapolitan pizza. Their pizza was not made in Naples or imported from Italy. The chef who prepared it may not have a drop of Italian blood in their veins. But the ingredients, appearance and taste may match really well with what tourists would expect to find at a great restaurant in Naples. Newman calls that categorical authenticity.
And finally, there is the authenticity that comes from our values and beliefs. This is the kind that many voters find wanting in politicians and elected leaders who say one thing but do another. It is what admissions officers look for in college essays.
In my own research, I’ve also seen that authenticity can relate to our expectations about what tools and activities are involved in creating things.
For example, when you see a piece of custom furniture that claims to be handmade, you probably assume that it wasn’t literally made by hand – that all sorts of modern tools were nonetheless used to cut, shape and attach each piece. Similarly, if an architect uses computer software to help draw up building plans, you still probably think of the product as legitimate and original. This is because there’s a general understanding that those tools are part of what it takes to make those products.
In most of your quick judgments of authenticity, you don’t think much about these dimensions. But with generative AI, you will need to.
That’s because back when it took a lot of time to produce original new content, there was a general assumption that it required skill to create – that it only could have been made by skilled individuals putting in a lot of effort and acting with the best of intentions.
These are not safe assumptions anymore.
How to deal with the looming authenticity crisis
Generative AI thrives on exploiting people’s reliance on categorical authenticity by producing material that looks like “the real thing.”
So it’ll be important to disentangle historical and categorical authenticity in your own thinking. Just because a recording sounds exactly like Drake – that is, it fits the category expectations for Drake’s music – it does not mean that Drake actually recorded it. The great essay that was turned in for a college writing class assignment may not actually be from a student laboring to craft sentences for hours on a word processor.
If it looks like a duck, walks like a duck and quacks like a duck, everyone will need to consider that it may not have actually hatched from an egg.
Also, it’ll be important for everyone to get up to speed on what these new generative AI tools really can and can’t do. I think this will involve ensuring that people learn about AI in schools and in the workplace, and having open conversations about how creative processes will change with AI being broadly available.
Writing papers for school in the future will not necessarily mean that students have to meticulously form each and every sentence; there are now tools that can help them think of ways to phrase their ideas. And creating an amazing picture won’t require exceptional hand-eye coordination or mastery of Adobe Photoshop and Adobe Illustrator.
Finally, in a world where AI operates as a tool, society is going to have to consider how to establish guardrails. These could take the form of regulations, or the creation of norms within certain fields for disclosing how and when AI has been used.
Does AI get credited as a co-author on writing? Is it disallowed on certain types of documents or for certain grade levels in school? Does entering a piece of art into a competition require a signed statement that the artist did not use AI to create their submission? Or does there need to be new, separate competitions that expressly invite AI-generated work?
These questions are tricky. It may be tempting to simply deem generative AI an unacceptable aid, in the same way that calculators are forbidden in some math classes.
However, sequestering new technology risks imposing arbitrary limits on human creative potential. Would the expressive power of images be what it is now if photography had been deemed an unfair use of technology? What if Pixar films were deemed ineligible for the Academy Awards because people thought computer animation tools undermined their authenticity?
The capabilities of generative AI have surprised many and will challenge everyone to think differently. But I believe humans can use AI to expand the boundaries of what is possible and create interesting, worthwhile – and, yes, authentic – works of art, writing and design.
The light and dark sides of AI have been in the public spotlight for many years. Think facial recognition, algorithms making loan and sentencing recommendations, and medical image analysis. But the impressive – and sometimes scary – capabilities of ChatGPT, DALL-E 2 and other conversational and image-conjuring artificial intelligence programs feel like a turning point.
Generative AI has been around for nearly a decade, as long-standing worries about deepfake videos can attest. Now, though, the AI models have become so large and have digested such vast swaths of the internet that people have become unsure of what AI means for the future of knowledge work, the nature of creativity and the origins and truthfulness of content on the internet.
Here are five articles from our archives the take the measure of this new generation of artificial intelligence.
1. Generative AI and work
A panel of five AI experts discussed the implications of generative AI for artists and knowledge workers. It’s not simply a matter of whether the technology will replace you or make you more productive.
University of Tennessee computer scientist Lynne Parker wrote that while there are significant benefits to generative AI, like making creativity and knowledge work more accessible, the new tools also have downsides. Specifically, they could lead to an erosion of skills like writing, and they raise issues of intellectual property protections given that the models are trained on human creations.
University of Colorado Boulder computer scientist Daniel Acuña has found the tools to be useful in his own creative endeavors but is concerned about inaccuracy, bias and plagiarism.
University of Michigan computer scientist Kentaro Toyama wrote that human skill is likely to become costly and extraneous in some fields. “If history is any guide, it’s almost certain that advances in AI will cause more jobs to vanish, that creative-class people with human-only skills will become richer but fewer in number, and that those who own creative technology will become the new mega-rich.”
Florida International University computer scientist Mark Finlayson wrote that some jobs are likely to disappear, but that new skills in working with these AI tools are likely to become valued. By analogy, he noted that the rise of word processing software largely eliminated the need for typists but allowed nearly anyone with access to a computer to produce typeset documents and led to a new class of skills to list on a resume.
University of Colorado Anschutz biomedical informatics researcher Casey Greene wrote that just as Google led people to develop skills in finding information on the internet, AI language models will lead people to develop skills to get the best output from the tools. “As with many technological advances, how people interact with the world will change in the era of widely accessible AI models. The question is whether society will use this moment to advance equity or exacerbate disparities.”
2. Conjuring images from words
Generative AI can seem like magic. It’s hard to imagine how image-generating AIs can take a few words of text and produce an image that matches the words.
Hany Farid, a University of California, Berkeley computer scientist who specializes in image forensics, explained the process. The software is trained on a massive set of images, each of which includes a short text description.
“The model progressively corrupts each image until only visual noise remains, and then trains a neural network to reverse this corruption. Repeating this process hundreds of millions of times, the model learns how to convert pure noise into a coherent image from any caption,” he wrote.
3. Marking the machine
Many of the images produced by generative AI are difficult to distinguish from photographs, and AI-generated video is rapidly improving. This raises the stakes for combating fraud and misinformation. Fake videos of corporate executives could be used to manipulate stock prices, and fake videos of political leaders could be used to spread dangerous misinformation.
Farid explained how it’s possible to produce AI-generated photos and video that contain watermarks verifying that they are synthetic. The trick is to produce digital watermarks that can’t be altered or removed. “These watermarks can be baked into the generative AI systems by watermarking all the training data, after which the generated content will contain the same watermark,” he wrote.
4. Flood of ideas
For all the legitimate concern about the downsides of generative AI, the tools are proving to be useful for some artists, designers and writers. People in creative fields can use the image generators to quickly sketch out ideas, including unexpected off-the-wall material.
AI as an idea generator for designers.
Rochester Institute of Technology industrial designer and professor Juan Noguera and his students use tools like DALL-E or Midjourney to produce thousands of images from abstract ideas – a sort of sketchbook on steroids.
“Enter any sentence – no matter how crazy – and you’ll receive a set of unique images generated just for you. Want to design a teapot? Here, have 1,000 of them,” he wrote. “While only a small subset of them may be usable as a teapot, they provide a seed of inspiration that the designer can nurture and refine into a finished product.”
5. Shortchanging the creative process
However, using AI to produce finished artworks is another matter, according to Nir Eisikovits and Alec Stubbs, philosophers at the Applied Ethics Center at University of Massachusetts Boston. They note that the process of making art is more than just coming up with ideas.
The hands-on process of producing something, iterating the process and making refinements – often in the moment in response to audience reactions – are indispensable aspects of creating art, they wrote.
“It is the work of making something real and working through its details that carries value, not simply that moment of imagining it,” they wrote. “Artistic works are lauded not merely for the finished product, but for the struggle, the playful interaction and the skillful engagement with the artistic task, all of which carry the artist from the moment of inception to the end result.”
Editor’s note: This story is a roundup of articles from The Conversation’s archives.
Effective passwords are cumbersome, all the more so when reinforced by two-factor authentication. But the need for authentication and secure access to websites is as great as ever. Enter passkeys.
Passkeys are digital credentials stored on your phone or computer. They are analogous to physical keys. You access your passkey by signing in to your device using a personal identification number (PIN), swipe pattern or biometrics like fingerprint or face recognition. You set your online accounts to trust your phone or computer. To break into your accounts, a hacker would need to physically possess your device and have the means to sign in to it.
As a cybersecurity researcher, I believe that passkeys not only provide faster, easier and more secure sign-ins, they minimize human error in password security and authorization steps. You don’t need to remember passwords for every account and don’t need to use two-factor authentication.
How passkeys work
Passkeys are generated via public-key cryptography. They use a public-private key pair to ensure a mathematically protected private relationship between users’ devices and the online accounts being accessed. It would be nearly impossible for a hacker to guess the passkey – hence the need to physically possess the device the passkey is accessed from.
Passkeys consist of a long private key – a long string of encrypted characters – created for a specific device. Websites cannot access the value of the passkey. Rather, the passkey verifies that a website possesses the corresponding public key. You can use the passkey from one device to access a website using another device. For example, you can use your laptop to access a website using the passkey on your phone by authorizing the login from your phone. And if you lose your phone, the passkey can be stored securely in the cloud with the phone’s other data, which can be restored to a new phone.
Passkeys explained in 76 seconds.
Why passkeys matter
Passwords can be guessed, phished or otherwise stolen. Security experts advise users to make their passwords longer with more characters, mixing alphanumeric and special symbols. A good password should not be in the dictionary or in phrases, have no consecutive letters or numbers, but be memorable. Users should not share them with anyone. Last but not least, users should change passwords every six months at minimum for all devices and accounts. Using a password manager to remember and update strong passwords helps but can still be a nuisance.
Even if you follow all of the best practices to keep your passwords safe, there is no guarantee of airtight security. Hackers are continuously developing and using software exploits, hardware tools and ever-advancing algorithms to break these defenses. Cybersecurity experts and malicious hackers are locked in an arms race.
Passkeys remove the onus from the user to create, remember and guard all their passwords. Apple, Google and Microsoft are supporting passkeys and encourage users to use them instead of passwords. As a result, passkeys are likely to soon overtake passwords and password managers in the cybersecurity battlefield.
However, it will take time for websites to add support for passkeys, so passwords aren’t going to go extinct overnight. IT managers still recommend that people use a password manager like 1Password or Bitwarden. And even Apple, which is encouraging the adoption of passkeys, has its own password manager.


 Still from ‘All watched over by machines of loving grace’ by Memo Akten, 2021. Created using custom AI software.
Still from ‘All watched over by machines of loving grace’ by Memo Akten, 2021. Created using custom AI software.
 AI chatbots and image generators run on thousands of computers housed in data centers like this Google facility in Oregon.
AI chatbots and image generators run on thousands of computers housed in data centers like this Google facility in Oregon.






{kind=link}