One way to acquire data for your research or personal data projects is to download data, known as scraping, directly from websites. There are many ways to go about solving a problem of getting data from a website. Some non-technical methods are available but today, we are going to use the Python programming language to scrape some data from a website data table.
In this brief tutorial, we will get tabular data from Wikipedia. We will use the popular Python libraries Pandas and Requests.
First, we need to install the libraries.
pip install pandas pip install requests
Next, we start coding. Import or call the libraries we are going to use.
import pandas as pd import requests
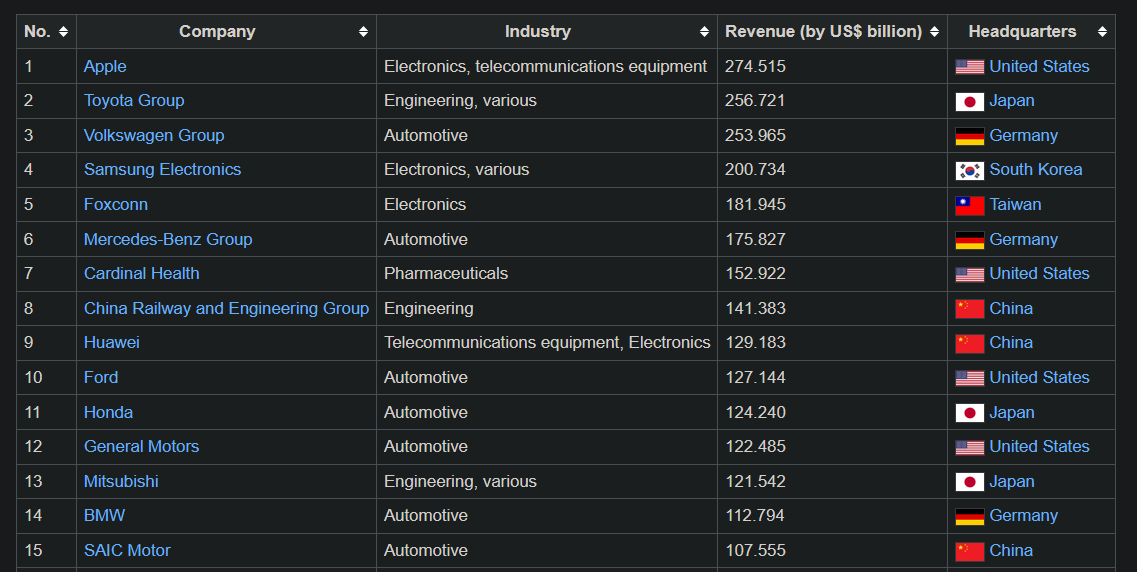
webpage = 'https://en.wikipedia.org/wiki/List_of_largest_manufacturing_companies_by_revenue'
page = requests.get(webpage) manufacturing_data = pd.read_html(page.text)
first_table = manufacturing_data[0]
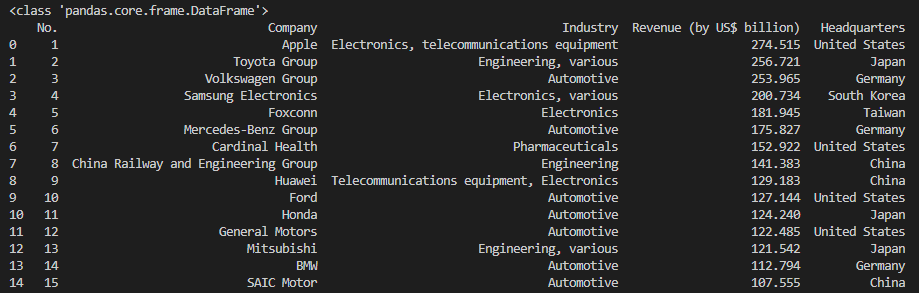
print(first_table[0:15])
# specify your folder location data_folder = 'C:/Users/Name/Folder_Location'
first_table.to_csv('{}/manufacturing.csv'.format(data_folder), index=False)

Now, we have downloaded our scraped data into a CSV spreadsheet. We have completed our mission starting with scraping a table online and finishing with the downloaded CSV data.
One thing you will want to consider before web scraping is whether the site (or information) you are scraping has any copyrighted content or other issues that may be against the terms and conditions of the site.
For more information on the legality of web scraping check out these links:
Web scraping is legal, US appeals court reaffirms – TechCrunch
HiQ Labs v. LinkedIn Case of Web Scraping
Article by Zachary Storella – See more programming posts on our Python Page